Apr 13, 2026
LitXBench: A Benchmark for Extracting Experiments from Materials Literature

We built a benchmark to measure how well LLMs can extract experiments from materials science papers, and found that most pipelines task LLMs incorrectly, leading to inaccurate extractions.
There is a lot of excitement around simulating materials in software, but these models can only work with lab-proven experimental data. And existing tools for extracting data from academic literature are often limited and inaccurate.
Today we’re excited to share LitXBench, a benchmark framework for evaluating LLM performance on scientific literature extraction, and LitXAlloy, a dense benchmark derived from 19 experimental alloy papers totalling 1,426 target values.
By recording experimental data from literature in code, our team and the entire industry can gather a higher volume of more accurate information and push materials science forward faster.
Why This Matters
At Radical we combine AI software and a physical autonomous lab to rapidly discover new materials. The faster we do that, the more we can speed breakthrough performance in critical industries like aerospace, automotive, energy, manufacturing, and semiconductors.
Before launching this benchmark, we had access to over 5 million pages of research papers with keyword-level indexing. When we run our agentic software, 100 run concurrently, reading 100 relevant papers each, then analyze those prior findings before bringing hypotheses to the physical automated lab. We consider this final step the most important—simulations alone are not nearly as meaningful as proven, characterized samples of novel alloys.
But how can we get to the smartest experiments faster and optimize what we spend time on in the lab? The introduction of LitXBench and LitXAlloy allows us to build extraction methods to index experiments much more accurately. For example, we can now search “strongest material annealed over 800°C containing titanium” instead of reviewing every keyword-based search result for “titanium” and sort through the papers that contain it.
An Industry-Wide Quality Control Challenge
Our industry has been flying not just blind, but with incorrect navigation.
The popular MPEA dataset, one of the most comprehensive multi-principal element alloy datasets available, extracts 33.4 measurements per paper, making it insufficient to benchmark extraction methods, whereas our team’s benchmark contains an average of 74.8. In 18 overlapping papers, LitXAlloy delivers an additional 745 values.
Subdividing for processing or properties dwindles the counts dismally: For example, only 95 entries were made from powders, and only 10 of those have an observed BCC phase. Numbers this small make it difficult to train models on processing-condition-specific behavior.
While MPEA has been a valuable resource for the materials science community, by design it has limitations that make it challenging to correct errors within it. LitXAlloy was built to be easily auditable, and this quality-oriented approach reveals a whopping 13% disagreement with MPEA values.
Automated extraction has been the proposed solution, but until now, the field has lacked a benchmark rigorous enough to evaluate whether extraction methods work. Prior benchmarks haven’t offered exact ground-truth annotations, released eval sets, or documented annotation methodology well enough to trust. Without a credible ground truth, comparing methods is not possible.
What We Built
LitXBench is a framework for benchmarking experimental data extraction from scientific literature in a way that makes evaluation auditable and reproducible across methods. It prescribes how extraction targets should be structured, how categories should be represented, and how benchmarks should be stored.
LitXAlloy is the first benchmark built on this framework: 1,426 measurements hand-extracted from 19 alloy papers, with all values reviewed using LLM-assisted scrutiny. Our team spent roughly 1.1 billion Claude Code tokens to catch errors that human annotators missed after reading each paper multiple times.
Three design decisions separate LitXBench from prior work
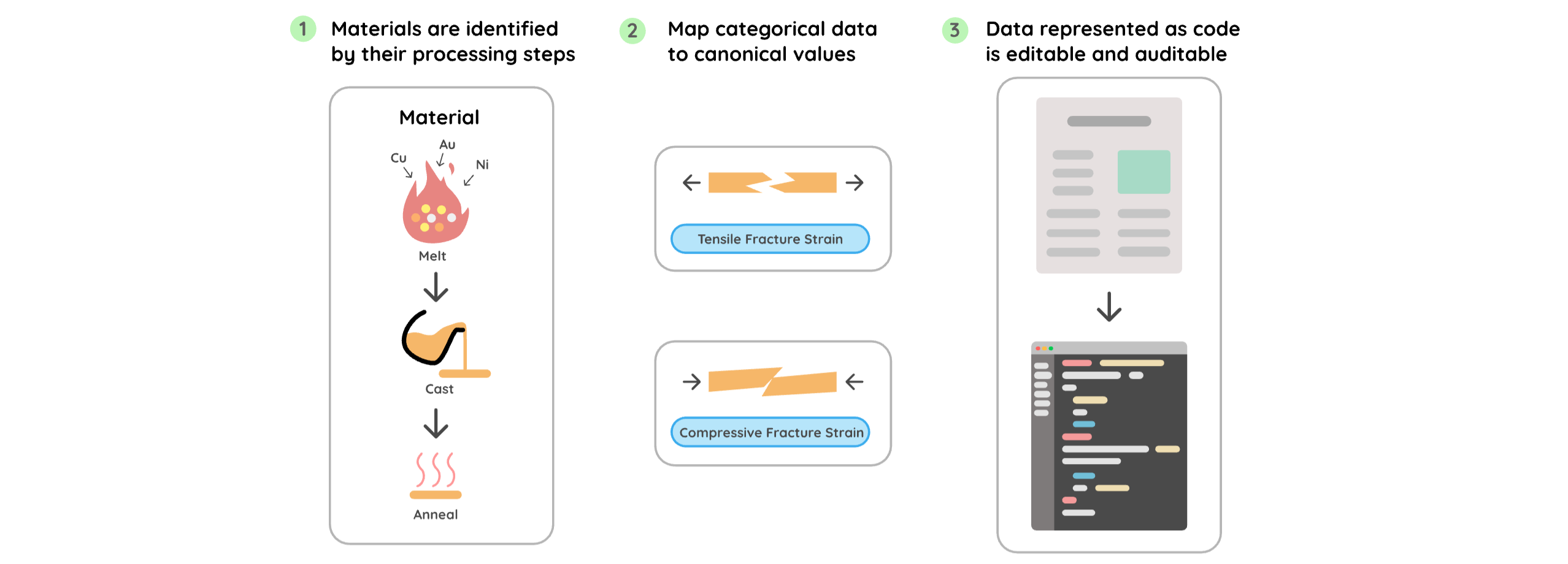
We identify materials by their processing history, not just composition. A material is not equal to a composition. Two samples with identical elemental ratios but different spark plasma sintering pressures are different materials with different properties. Systems that index by composition collapse this distinction. In one paper in LitXAlloy, two materials share the composition Fe24.1Co24.1Cr24.1Ni24.1Mo3.6 but were sintered at different pressures. A composition-centric extractor produces a one-to-many mapping between the composition and its properties, which is not scientifically valid. LitXBench represents each material as a directed acyclic graph of processing events, making the synthesis history the primary identifier.
We map categorical values to canonical enums at extraction time. Fracture strain measured under compression and fracture strain measured under tension are different quantities. A system that extracts both as "fracture strain" will junk up data unless a good samaritan scientist painstakingly goes back through the literature to correct it. LitXBench requires extraction methods to map all categorical fields to canonical values at the moment of extraction, while the model still has context to distinguish them. Post-hoc canonicalization makes systematic mistakes in the ambiguous cases where context matters most. KnowMat2 illustrates this: It correctly extracts compressive yield strength for one alloy, then a post-processing model maps it to tensile yield strength because it lacked the context to recognize the test type.
We store the benchmark as code, not CSV or JSON. Inspired by Terraform's infrastructure-as-code approach, LitXAlloy represents each extracted experiment as a Python object. This provides compile-time and runtime validation, enables semantic checks specific to the material class (all melting events must be followed by a casting step; compositions must sum to 100%), and makes the benchmark editable without external tooling. Source fields trace every extracted value back to the table or sentence it came from. And when experiments live in code, reviewers can submit error corrections as pull requests.
See our findings for how various models performed against benchmarks in Curtis Chong’s preprint here.
@RadicalAI
View onUnable to load tweets. Please check back later.