Feb 10, 2026
Leveraging Experimental Data Beyond Language: A Multimodal Benchmark

In our pursuit of breakthrough material discoveries, Radical’s ML team has seen clear gains from incorporating vision data into models. Here, we share our process for an approach that can apply across domains, and a benchmark and post-training dataset that has helped move our particular work forward.
Most AI systems for science are trained to reason over text, but much of the world’s scientific knowledge does not live in words. This is especially true in materials science, where critical information is encoded in diffraction patterns, microscopy images, thermal curves, and other experimental artifacts.
In our work at Radical AI, we are exploring how vision-language models (VLMs) can be used to ground scientific reasoning in experimental data. Our goal is not simply to build models that can describe images, but to create systems that learn from experiments the way scientists do: by combining foundational knowledge with visual and quantitative evidence.
To that end, our new paper introduces an approach to materials AI built around experimental grounding:
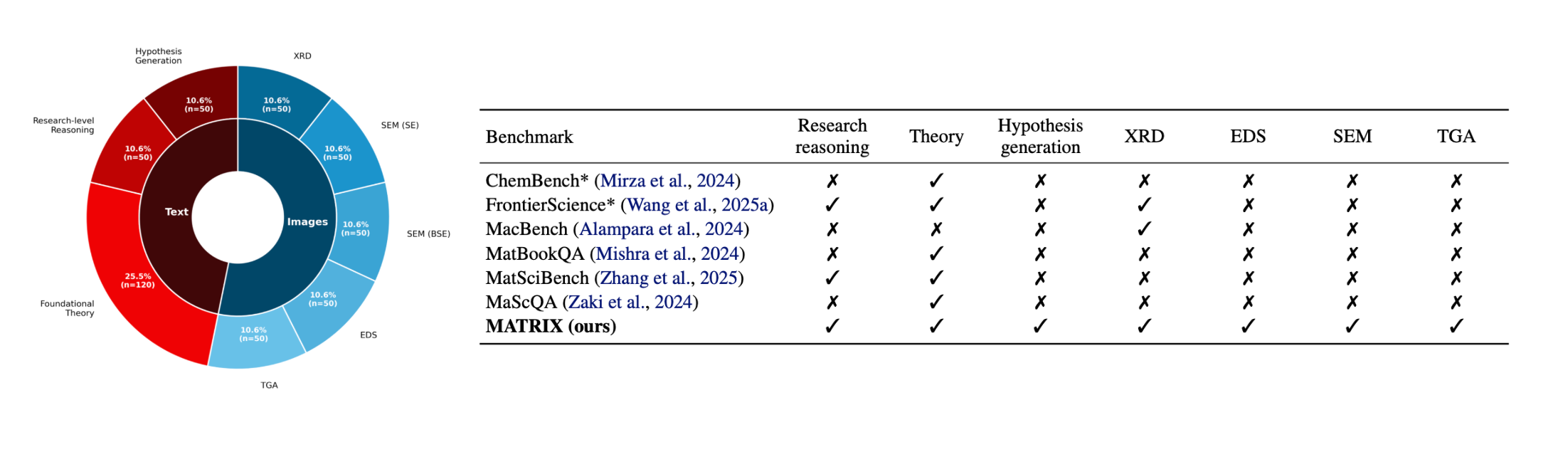
- We introduce MATRIX, a multimodal benchmark for scientific reasoning in materials science and its corresponding MATRIX-PT post-training dataset.
- We isolate the effects of post-training and demonstrate that aligned image–description pairs yield consistent gains in text-only reasoning on out-of-distribution tasks.
- We demonstrate that post-training on foundational and applied vision and textual materials science tasks has transferable gains on other science benchmarks.
Beyond the paper, Radical AI is applying these same principles internally to build and strengthen our multimodal vision-language models. The post-training approach demonstrated here serves as a case study: Even with modest, publicly available data, aligned multimodal supervision produces measurable gains in scientific reasoning, results that point toward what becomes possible with larger-scale, higher-quality proprietary datasets.
The Need for a New Benchmark
Scientific reasoning in the laboratory is inherently multimodal. A materials scientist doesn’t read an XRD plot in isolation; they interpret it in the context of composition, processing history, phase equilibria, microstructure, and competing mechanisms. They connect SEM contrast and morphology to phase segregation, oxidation pathways, precipitation, or deformation modes.
In practice, the same scientific question often requires combining multiple types of evidence. Despite this, the field lacks good diagnostics to evaluate whether multimodal training produces meaningful gains in scientific reasoning rather than improvements limited to superficial pattern matching and factual recall.
Our Solution and Approach
MATRIX is intended to fill this gap, serving as a multimodal benchmark for materials science reasoning that evaluates both text-only scientific reasoning and the interpretation of real experimental artifacts, inside one unified framework.

MATRIX spans four task families, constructed from open‑access research papers and postgraduate-level materials science coursework:
- Foundational theory reasoning: mechanism-grounded explanations of core concepts
- Research-level reasoning: open-ended, multistep reasoning in realistic scenarios
- Hypothesis generation: proposing plausible next steps from incomplete context
- Experimental interpretation across real characterization modalities, including:
- SEM in BSE and SE modes
- XRD patterns
- EDS maps/spectra
- TGA curves
The Question We Actually Care About
A lot of multimodal work implicitly assumes: “If you show the model images during training, it’ll get better at image tasks.” But the more interesting question is: Does aligned multimodal supervision change the internal representations that support scientific reasoning, such that learning from experiments improves reasoning even when images are absent at inference time?
To test that, we need:
- A benchmark where text‑only reasoning can be evaluated without images at inference time.
- Controlled training conditions that isolate text‑only vs. vision‑only vs. joint post‑training.
- A way to prove the gains come from correct image-text alignment, not spurious correlations or answer memorization. This is how we structured the post-training experiments, with MATRIX serving as a controlled diagnostic.
Our Findings
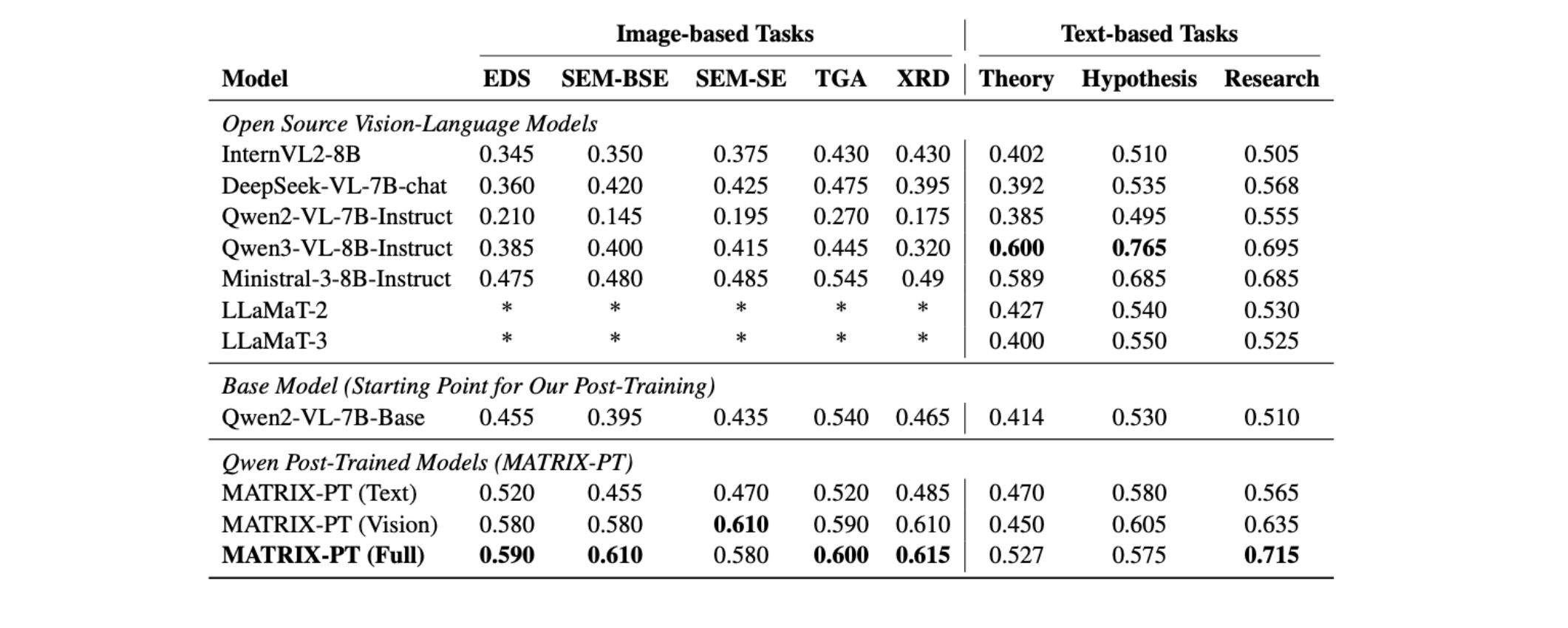
1. Current open models are much stronger on text than on experiments. Across representative open VLMs, text‑based scientific reasoning is generally stronger than experimental interpretation, especially for higher‑complexity modalities like SEM and XRD. This mismatch is exactly what one would expect if models learn superficial pattern matching and factual recall but struggle to map real experimental signals to mechanism.
2. Small amounts of aligned multimodal data can matter a lot. Even with relatively modest multimodal post‑training data, visual supervision improved experimental interpretation by 10–25% and also yielded 5–16% gains on text‑only scientific reasoning tasks, suggesting models can learn scientific abstractions from experiments that transfer to language‑only reasoning.
3. It transfers beyond materials benchmarks. We also see improvements on out‑of‑domain scientific benchmarks (including ScienceQA and PubMedQA), suggesting these effects aren’t purely materials trivia and instead reflect more generalizable scientific reasoning improvements.
Why We Care
At Radical AI, we are building a closed‑loop, AI-driven discovery flywheel:
- AI models generate hypotheses and design experiments.
- Robotic laboratories execute those experiments autonomously.
- Experimental results are captured and feed back into learning.
- Models improve, and the loop accelerates.
In this flywheel, it’s critical to measure not only how models perform on experimental interpretation, but whether improvements there translate into stronger text-based scientific reasoning, because both are required for a system that plans, executes, and learns from experiments. MATRIX enables that combined evaluation.
Moreover, the post-training results underscore the importance of closing the loop: Multimodal data from experiments enable measurable improvements in scientific reasoning. Notably, this paper demonstrates such improvements with only small amounts of publicly available data. Internally, we are scaling this approach with proprietary datasets of significantly higher quality and volume.
We are eager to hear what others are working on, and have made our model and dataset available on Hugging Face for those who want to see more.